





随着大数据时代的到来,实时数据处理的需求愈发凸显,作为开源的流处理平台,Apache Kafka在众多大数据应用中扮演着至关重要的角色,特别是在实时数据处理领域,Kafka以其高吞吐、低延迟的特性赢得了广泛的关注和应用,而在实际应用中,有时我们需要处理一种特殊的情况——重复消费,本文将介绍在12月市场上热门的Kafka实时重复消费的产品及其特点。
什么是Kafka实时重复消费?
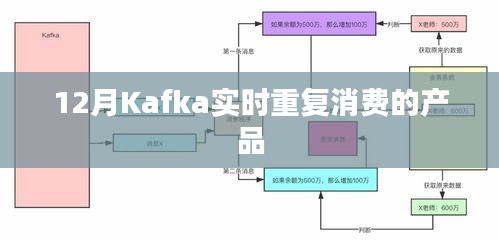
在Kafka的消费过程中,由于各种原因(如消费者处理速度跟不上消息生成速度、网络波动等),可能会出现消费者未能成功处理某条消息而再次接收到这条消息的情况,即消息的重复消费,对于某些应用来说,实时重复消费的处理机制能够保证数据的完整性和一致性,因此具有重要的实际意义。
热门产品介绍
1、Apache Kafka自身
Apache Kafka是一个开源的流处理平台,其强大的消息队列功能支持实时数据处理,Kafka提供了消息重复消费的基本机制,通过配置消费者参数,可以实现消息的可靠消费和重复消费,由于其开源特性和广泛的社区支持,Kafka在各种大数据应用中都有广泛的应用。
2、Confluent Platform
Confluent Platform是Confluent公司开发的基于Apache Kafka的平台,该平台提供了丰富的Kafka周边工具和服务,包括Kafka Connect、Kafka Streams等,在实时重复消费方面,Confluent Platform提供了强大的支持,包括自动检测并处理重复消息的功能,降低了开发者的处理难度。
3、Apache Flink
Apache Flink是一个流处理和批处理的开源框架,它集成了Kafka作为数据源和数据目标,支持实时数据流的处理和分析,在处理Kafka的重复消费问题时,Flink提供了丰富的API和机制,允许开发者方便地处理重复数据,Flink的高吞吐和低延迟特性使其成为处理Kafka实时重复消费的理想选择。
产品特点分析
1、Apache Kafka:作为开源的流处理平台,Kafka具有高度的灵活性和可扩展性,其强大的消息队列功能支持实时数据处理和重复消费,对于复杂的业务场景,可能需要开发者自行处理重复消费的逻辑。
2、Confluent Platform:该平台在Kafka的基础上提供了丰富的工具和服务,大大简化了开发者的开发难度,其自动检测和处理重复消息的功能降低了开发者在处理重复消费时的压力,作为一个商业产品,其成本可能相对较高。
3、Apache Flink:Flink在处理大数据流方面表现出色,其集成Kafka的能力也非常强大,在处理重复消费方面,Flink提供了丰富的API和机制,使得开发者能够方便地处理重复数据,Flink的高性能和低延迟特性使其成为许多企业的首选,与Confluent Platform相比,Flink的社区支持和专业服务的丰富程度可能稍逊一筹。
在处理Kafka的实时重复消费时,我们需要根据实际需求和应用场景选择合适的产品和工具,Apache Kafka、Confluent Platform和Apache Flink都是优秀的选择,它们各自具有不同的特点和优势,在实际应用中,我们可以根据需求选择合适的产品,以实现高效、稳定的实时数据处理。
转载请注明来自德仕美通,本文标题:《Kafka实时重复消费产品解析》






 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...